Detekce kůrovce s využitím dronů
Detekce kůrovce před jeho prvním jarním rojením s využitím dronu, multispektráního senzoru a aplikace využívající AI.

Detekce kůrovce před jeho prvním jarním rojením s využitím dronu, multispektráního senzoru a aplikace využívající AI.
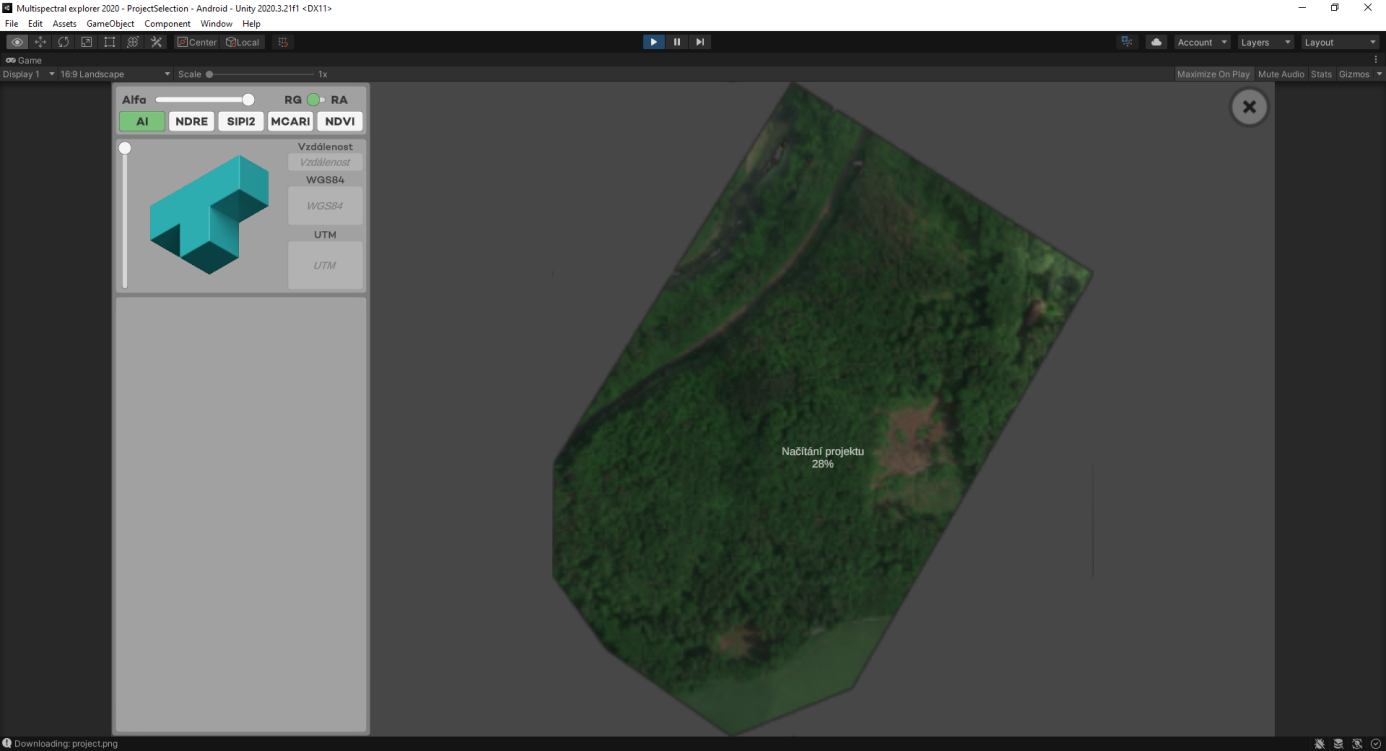
Ve spolupráci s naší sesterskou organizací SVS Plzeň (správce měsrských lesů) jsme v průběhu dvou let pracovali na projektu detekce kůrovce v konkrétním stromě. Dokážeme kůrovce odhalit díky snímkům pořízených multispektrální kamerou, které následně zpracováváme v aplikaci MultispectralExplorer využívajícím AI, který jsme sami vyvinuli. Detekce konkrétního stromu je možná ještě před prvním jarním rojením.
Detekovat kůrovce v konkrétním stromu před jeho prvním jarním rojením.
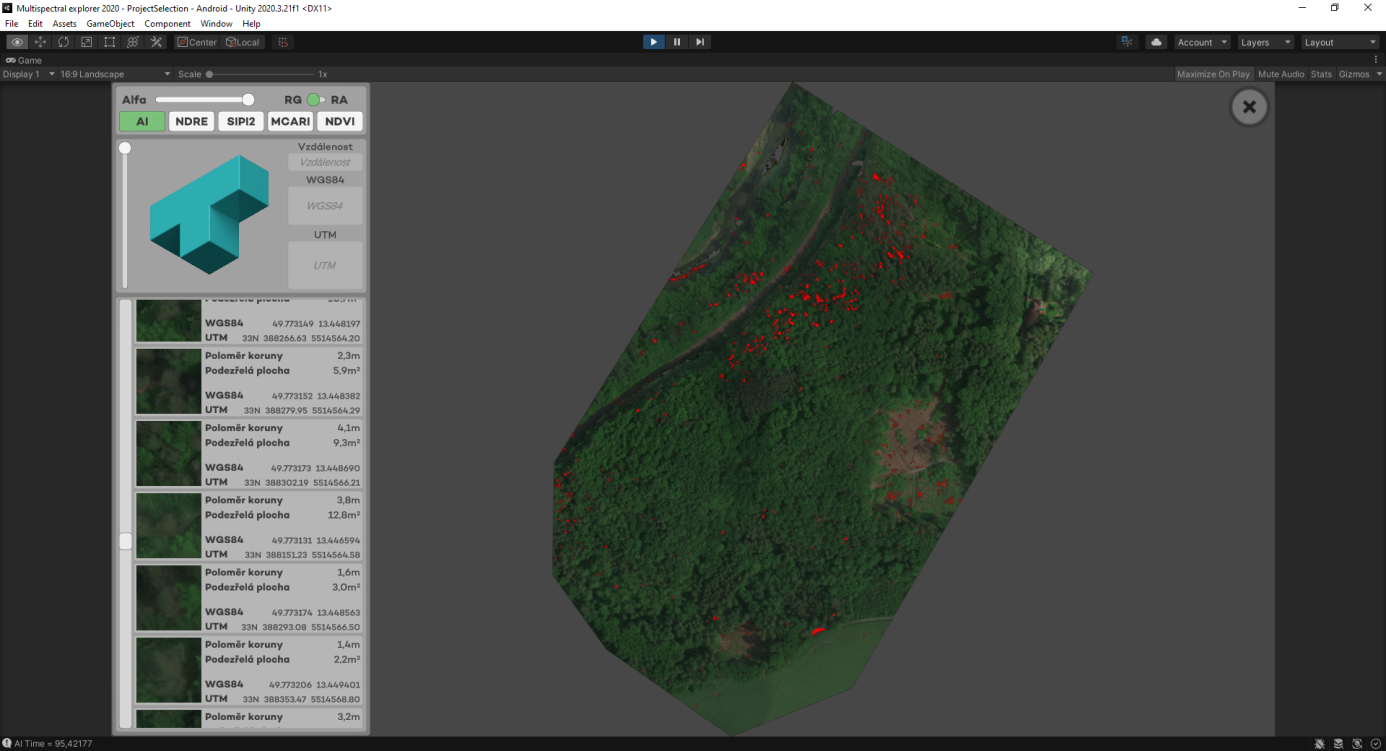
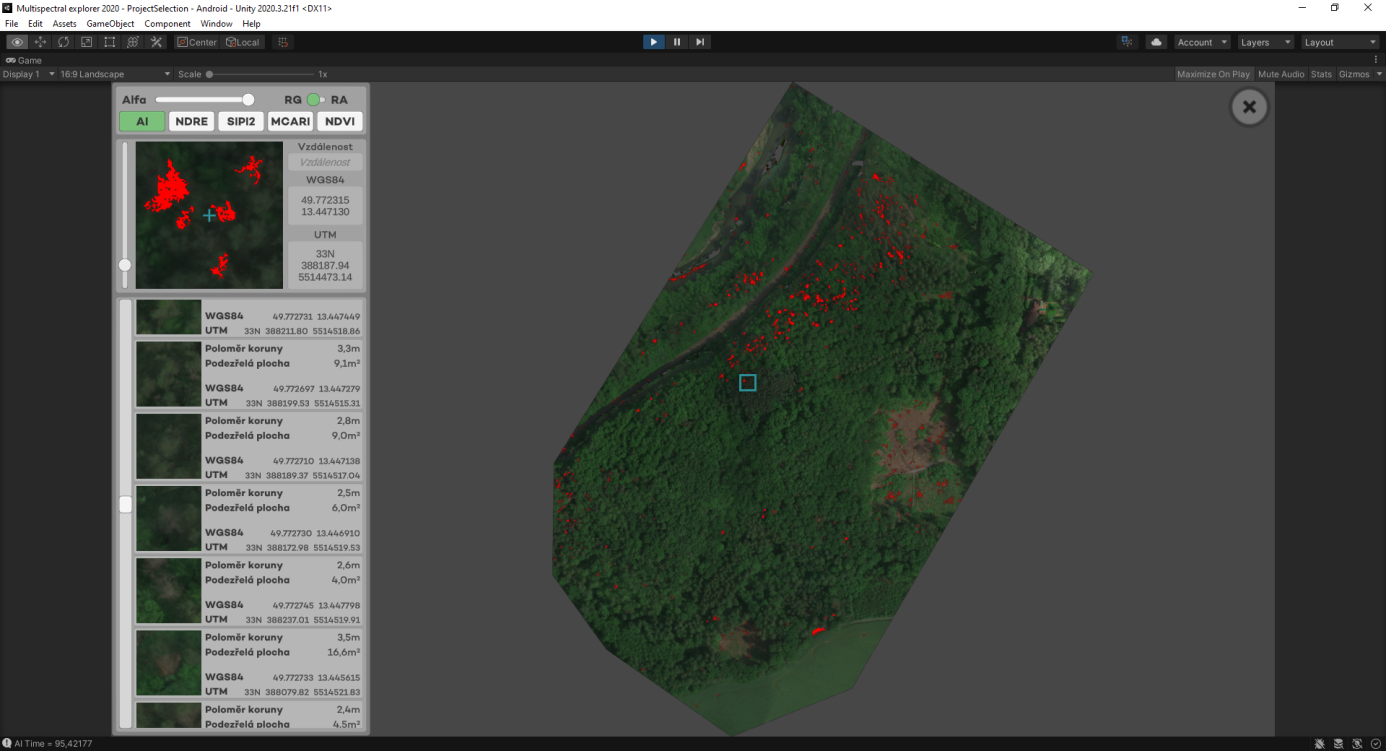
je mobilní aplikace, která primárně slouží jako nástroj pro včasné rozpoznání a nalezení kůrovce. Umožňuje automatické rozpoznání podezřelých stromů dříve, než je problém rozpoznatelný pouhým okem.
Aplikace pracuje s daty z multispektrální kamery, která je nesená dronem. Kamera snímá v pěti spektrech (R, G, B, NIR, RedEdge), ze kterých dokáže detekovat, jaké množství světla/potravy strom přijímá. Porovnávací metodou pak aplikace zjistí, jestli daný strom nevybočuje z normálu. Pokud ano, označí ho jako podezřelou vegetaci a přidá na seznam stromů, které je třeba zkontrolovat správcem lesa.
Vzhledem k základnímu principu této metody je aplikace schopná kůrovce odhalit 14 až 28 dní předtím, než dojde ke zreznutí stromu a přerojení brouka. Zároveň tato metoda zjistí i jiný druh napadení, nemoci, či přirozené zasychání stromů.
Aplikace je přímo napojená na náš cloud a všechna data jsou kdykoliv k dispozici online. Uživatel si může vybrané projekty stáhnout přímo do aplikace v tabletu. Díky tomu ho může aplikace vést k podezřelým stromům i bez přístupu k mobilním datům.
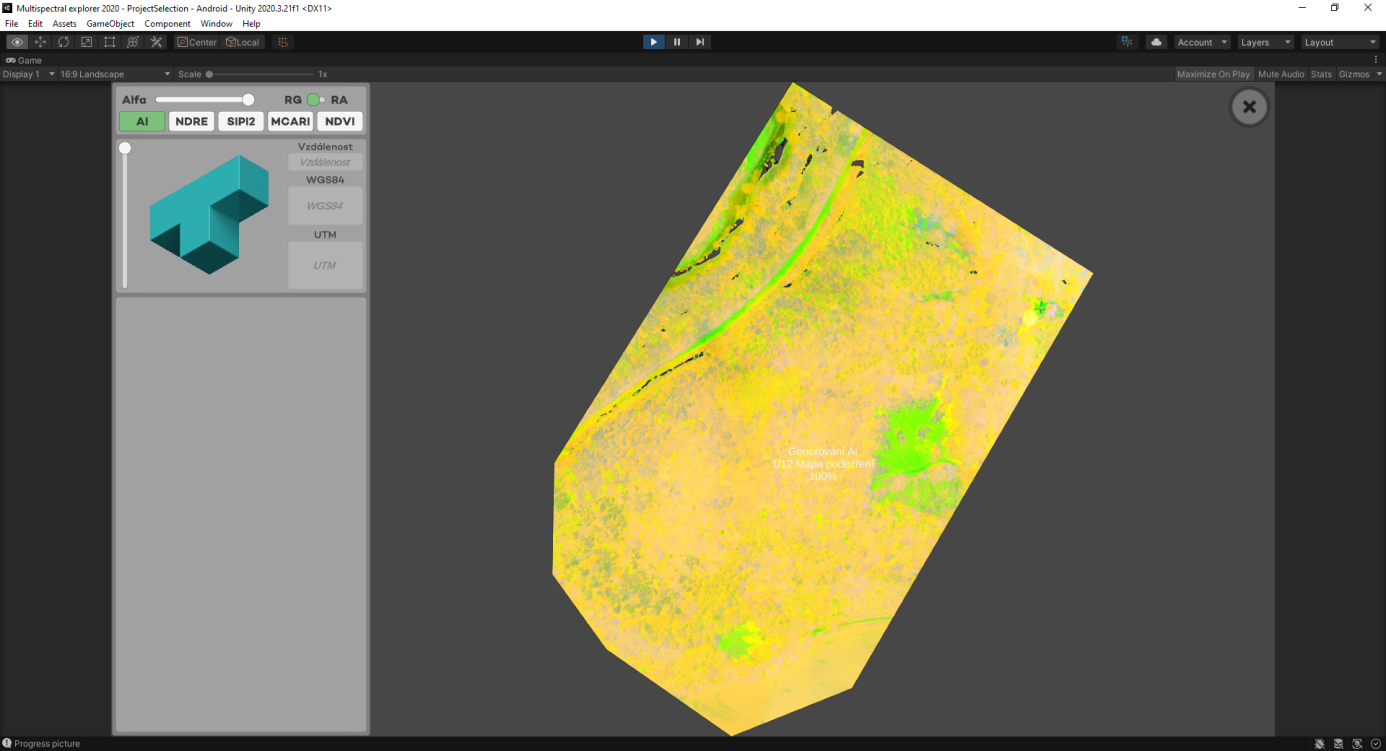
Mimo generování seznamu podezřelé vegetace, včetně GPS koordinátů jednotlivých stromů, poslouží aplikace i jako navigace nebo jako prohlížečka ostatních vegetačních indexů a spekter, které odborníkům pomáhají určit celkový stav lesa.
V současné chvíli probíhá vývoj řešení založeného na strojovém učení. V tomto případě se algoritmus sám učí rozpoznávat podezřelé oblasti. Není tedy nutné určovat pravidla, podle kterých jsou tyto oblasti definovány.
Systému jsou postupně předkládány různé vzorky dat společně s informací, zda se jedná o napadenou oblast či nikoliv. Tato fáze se nazývá trénovací a systém si sám hledá parametry, ve kterých se napadené a nenapadené oblasti odlišují. Po ukončení trénování je systém schopen na základě naučených pravidel sám rozhodovat.
Na přesnost tohoto přístupu má vliv několik faktorů z nichž pravděpodobně nejdůležitější je množství dat, která jsou použita pro trénování. Aby bylo možné mluvit o dostatečně obecné schopnosti rozlišovat mezi napadenou a nenapadenou oblastí, je třeba systému dodat řádově stovky až tisíce vzorků. Ideální je, aby množství napadených a nenapadených vzorků bylo přibližně stejné. Největší úskalí je tedy shromažďování těchto dat, jelikož dosud neexistuje veřejně dostupná databáze, která by tato data obsahovala.
V současné době máme k dispozici první verzi učícího se systému. S každým dalším rokem, kdy se nám podaří nasbírat nová data, je možné tento systém přetrénovat a zvýšit tak jeho přesnost i robustnost.
Ke zpracování nově nasnímaných dat bude sloužit server s operačním systémem Linux. Jakmile dojde k nalétání nové oblasti a získaná data se nahrají na předem určené místo, aplikace na serveru data automaticky zpracuje a výsledky v podobě pravděpodobnostních map zpřístupní aplikaci.